
Day by day, doing a data analysis is becoming easier and easier. I am waiting for the next news like this: Doing data analysis by just thinking! Hi Elon, if you are reading this one, please reach me via here, if you plan to do this, data analysis with thinking, I mean with neural link!
Jokes aside, if you plan to do data analysis more easily, especially using AI, you should definitely follow me, check my previous articles, or better yet, visit our platform and subscribe! You can even get an agent that fully automates the data analysis.
Let’s not get distracted from the content. In this article, we will use totally free Google Colab features to automate data analysis, and as usual, we will use a Kaggle dataset to do that. How cool is that, right? Let’s see the dataset first.
Machine Learning Job Postings in the US
Machine Learning Job Postings in the US: reference
Wonderful dataset! I always wondered what I had to do to land a job related to Machine Learning. I even bought a printed Machine Learning book and read it before sleeping!
Anyways, what can we conclude from this dataset? Let’s see the data dictionary.
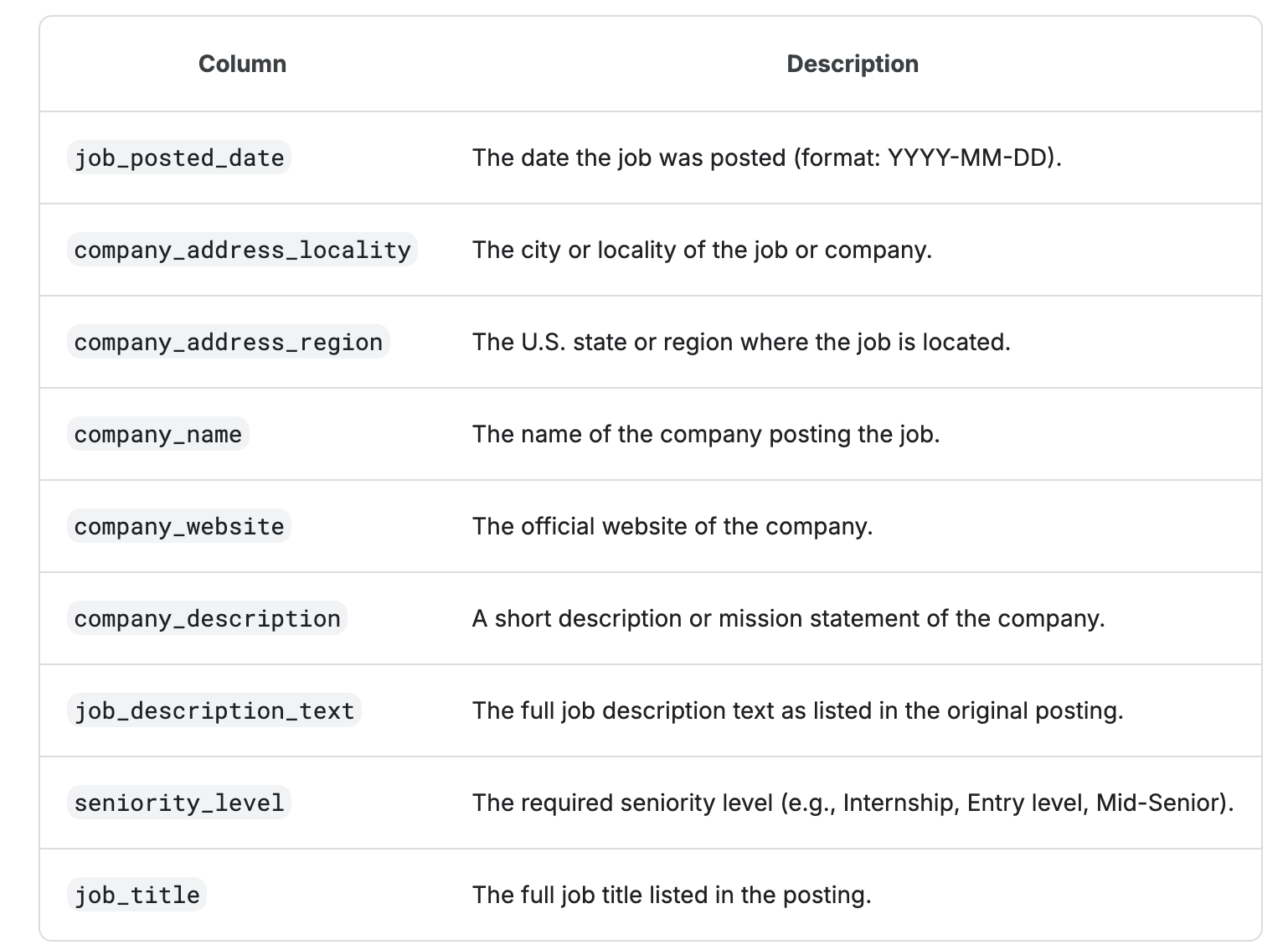
Data Definition Language
Good, now we have an overall knowledge of the dataset.
Data Analysis Colab

Visit here: https://colab.research.google.com/
Good, now click here and upload the file to the Colab.

Data Uploading
Great, let’s click on the analyze files with Gemini.

Analyze the file with Gemini
Wow, it asks me to upload the file once again, so we don’t need to upload it in the first place, I guess. Great. Let’s send the DDL to the Gemini
Data Analysis
Here is the DDL: [DDL Here]
And the dataset is attached.
Can you please do a data exploration?
You see the magic words above, but could it be done properly? I don’t know, let's see.

Tasks Plan
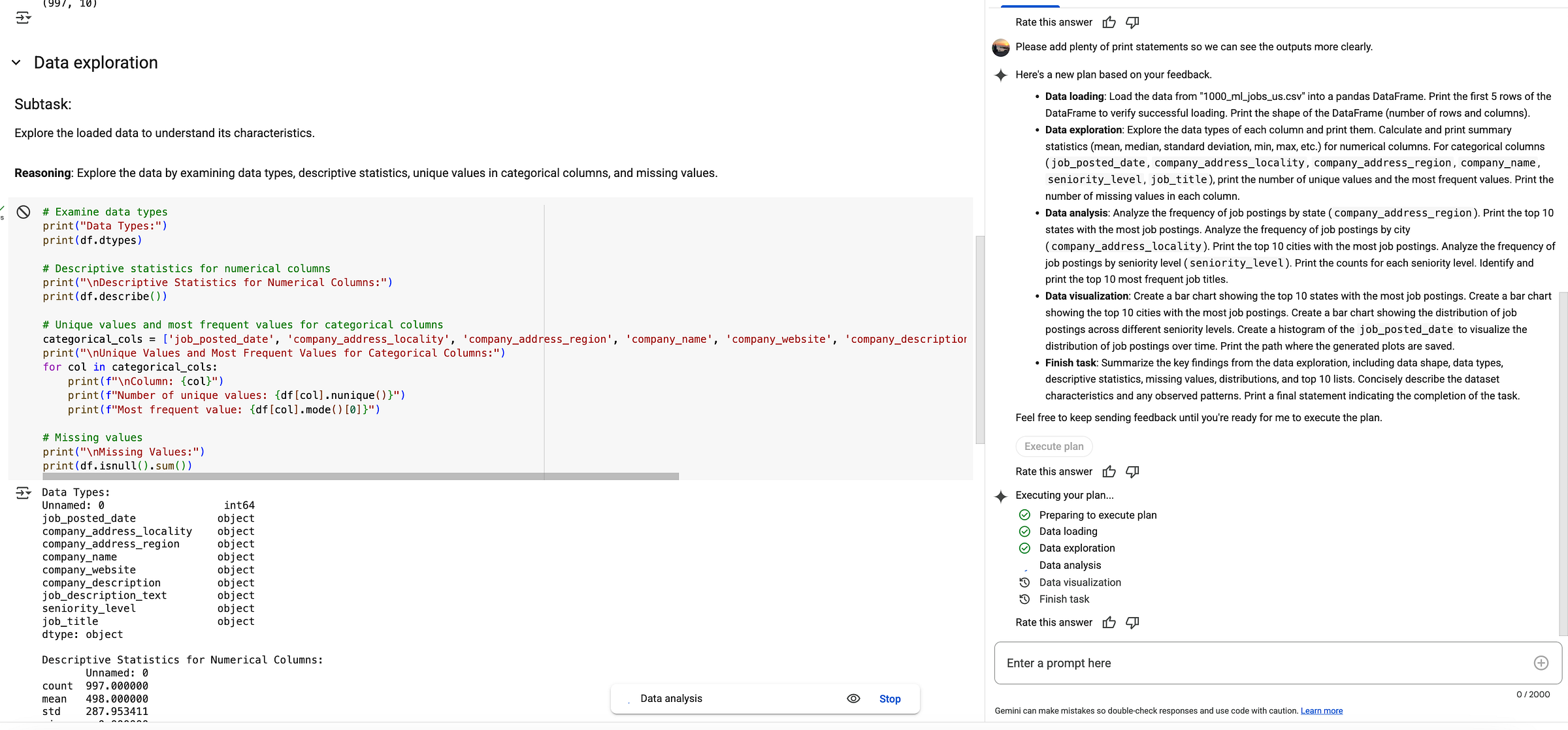
Good, it gives the task list, well, not touch it at first to see how it can do. Let’s just add one note:
Please add plenty of print statements so we can see the outputs more clearly.
The updated plan is like that;

Updated Plan
You know what to do, right? Just click on “Execute Plan”.

The plan is executing!
Also you see this under the screen;

Oo my god!

Automated Data Analysis started!
I thought it was another clickbait, but it was not! The data analysis is fully automated. Once you approve the task list, as you can see, the code is running and the explanations are added to the subsections like Data Exploration, check the left.
Data Visualization

Top 10 states with the most job postings
First of all I want to say hello to California! I would have written an explanation here, but it does not need me! It did everything by itself!
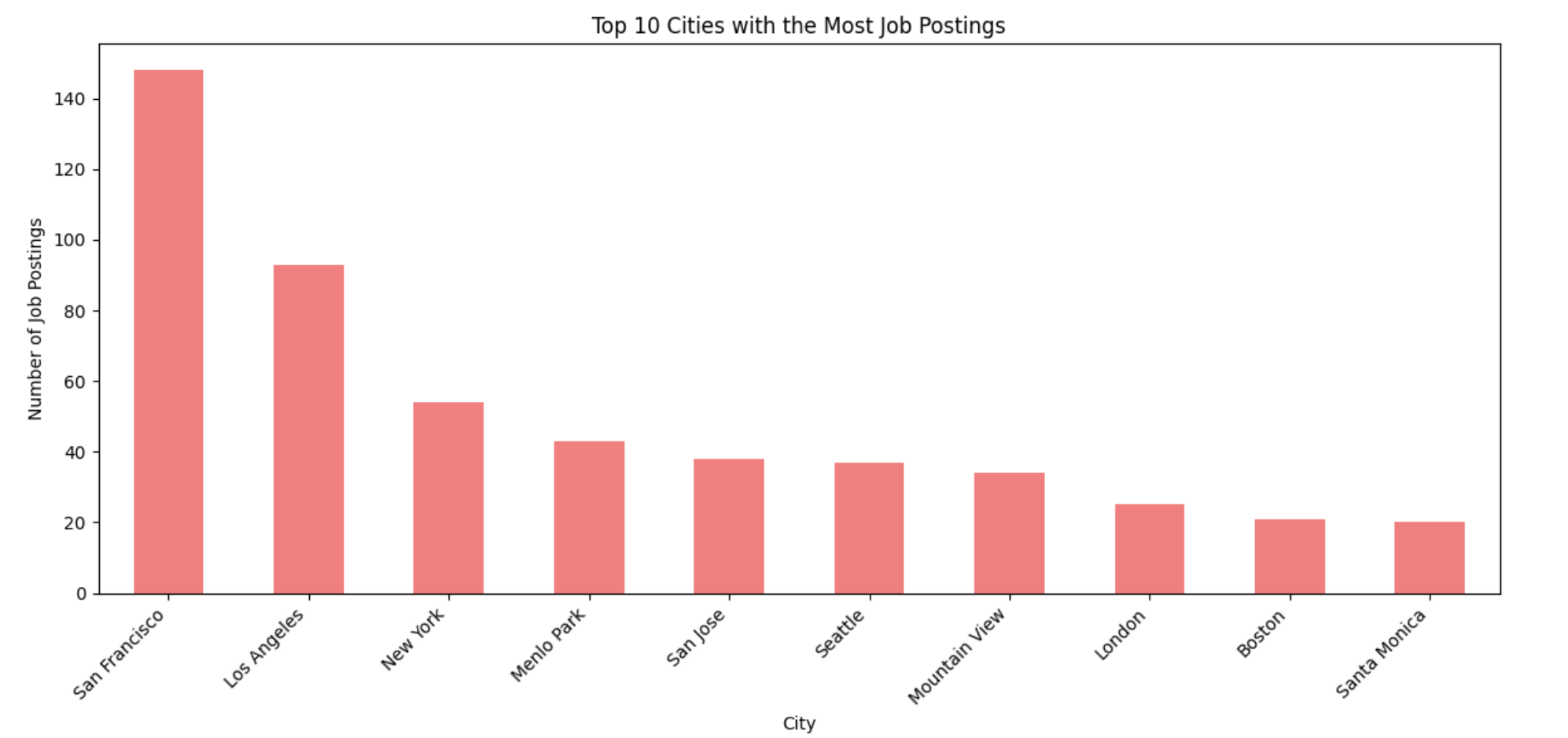
Top 10 cities with the Most job postings
Another hi goes to San Francisco, Silicon Valley, am I right? It continues.
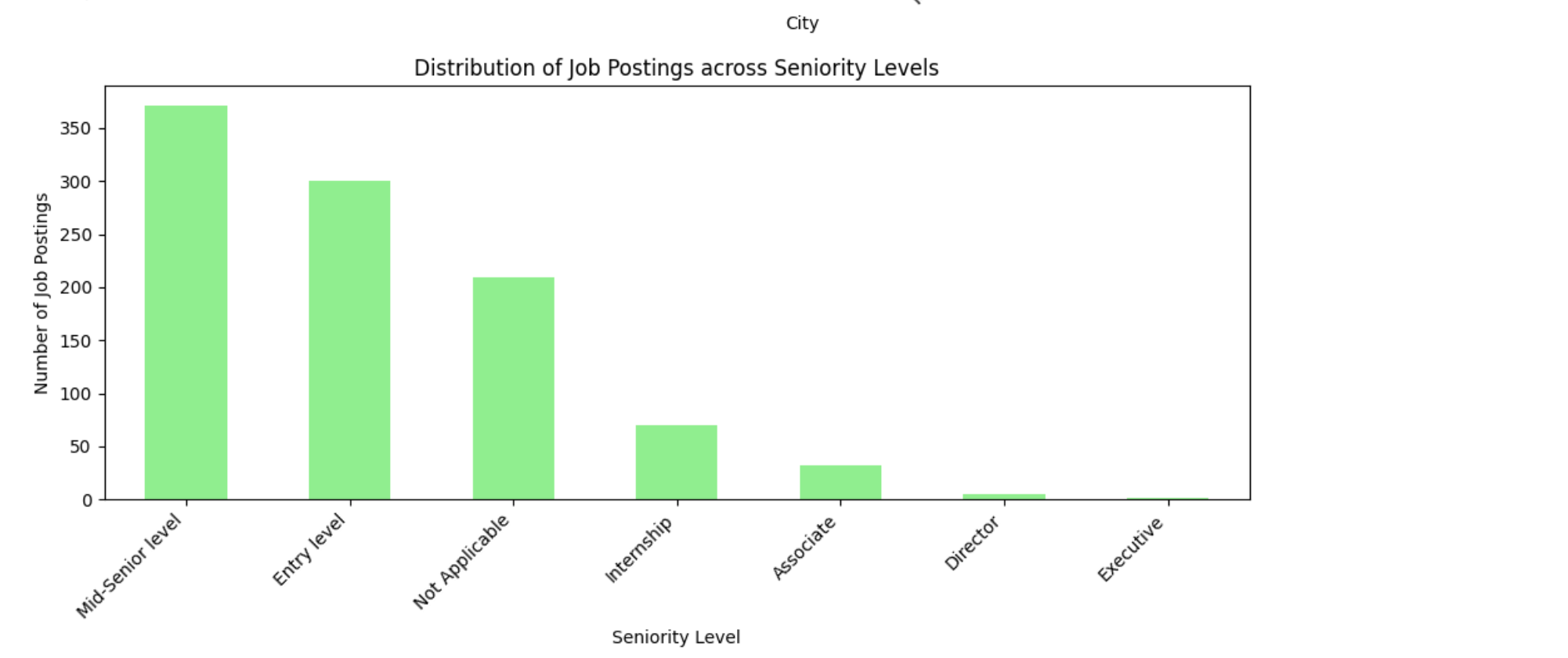
Seniority Level
If you are an entry-level data scientist, as you can see, there are a lot of job options. Let’s see the summary!

Testing
Let’s see everything at once. I installed this software just to write more explainable articles for you. It is a bit pricey, but for cases like this, it is very useful. Now let’s see what this tool does!
Testing
Final Question: What are the common points in the job descriptions?
Now let’s ask this question. Unfortunately, it won’t run this code after doing the analysis like above, but it provides the code.
After a few(three) errors, I successfully ran the code.

Here is the entire code it provides;
import pandas as pd
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import NMF
# Download necessary NLTK data (if you haven't already)
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
print("Downloading punkt tokenizer...")
nltk.download('punkt')
try:
nltk.data.find('corpora/stopwords')
except LookupError:
print("Downloading stopwords...")
nltk.download('stopwords')
# Add this block to download the 'punkt_tab' resource
try:
nltk.data.find('tokenizers/punkt_tab')
except LookupError:
print("Downloading punkt_tab tokenizer tables...")
nltk.download('punkt_tab')
# Assume 'df' is already loaded and contains the 'job_description_text' column
# --- Text Preprocessing ---
def preprocess_text(text):
if isinstance(text, str):
# Tokenize the text
tokens = word_tokenize(text.lower())
# Remove stop words and non-alphabetic tokens
stop_words = set(stopwords.words('english'))
filtered_tokens = [word for word in tokens if word.isalpha() and word not in stop_words]
return " ".join(filtered_tokens)
else:
return "" # Return an empty string for non-string values
df['processed_description'] = df['job_description_text'].apply(preprocess_text)
# --- Keyword Extraction using TF-IDF ---
print("\n--- Keyword Extraction (Top TF-IDF terms) ---")
# Create a TF-IDF vectorizer
tfidf_vectorizer = TfidfVectorizer(max_features=1000, max_df=0.95, min_df=2)
tfidf_matrix = tfidf_vectorizer.fit_transform(df['processed_description'])
# Get feature names
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
# Calculate the sum of TF-IDF scores for each word across all documents
sum_tfidf = tfidf_matrix.sum(axis=0)
# Create a dictionary of words and their sum of TF-IDF scores
tfidf_scores = [(word, sum_tfidf[0, idx]) for word, idx in tfidf_vectorizer.vocabulary_.items()]
# Sort the words by their TF-IDF scores in descending order
tfidf_scores = sorted(tfidf_scores, key=lambda x: x[1], reverse=True)
# Print the top 20 keywords
print("Top 20 keywords:")
for word, score in tfidf_scores[:20]:
print(f"{word}: {score:.2f}")
# --- Topic Modeling using NMF ---
print("\n--- Topic Modeling (NMF) ---")
# Apply Non-Negative Matrix Factorization (NMF)
n_components = 5 # You can adjust the number of topics
nmf = NMF(n_components=n_components, random_state=1, l1_ratio=.5, init='nndsvda')
nmf.fit(tfidf_matrix)
# Print the top words for each topic
print(f"Top words for each of the {n_components} topics:")
feature_names = tfidf_vectorizer.get_feature_names_out()
for topic_idx, topic in enumerate(nmf.components_):
print(f"Topic #{topic_idx + 1}:")
print(" ".join([feature_names[i] for i in topic.argsort()[:-10 - 1:-1]]))
# --- N-gram Analysis ---
print("\n--- N-gram Analysis (Top Bigrams and Trigrams) ---")
# Create a TF-IDF vectorizer for N-grams
ngram_vectorizer = TfidfVectorizer(ngram_range=(2, 3), max_features=1000, max_df=0.95, min_df=2)
ngram_matrix = ngram_vectorizer.fit_transform(df['processed_description'])
# Get N-gram feature names
ngram_feature_names = ngram_vectorizer.get_feature_names_out()
# Calculate the sum of TF-IDF scores for each N-gram
sum_ngram_tfidf = ngram_matrix.sum(axis=0)
# Create a dictionary of N-grams and their sum of TF-IDF scores
ngram_scores = [(ngram, sum_ngram_tfidf[0, idx]) for ngram, idx in ngram_vectorizer.vocabulary_.items()]
# Sort the N-grams by their TF-IDF scores
ngram_scores = sorted(ngram_scores, key=lambda x: x[1], reverse=True)
# Print the top 20 N-grams
print("Top 20 Bigrams and Trigrams:")
for ngram, score in ngram_scores[:20]:
print(f"{ngram}: {score:.2f}")
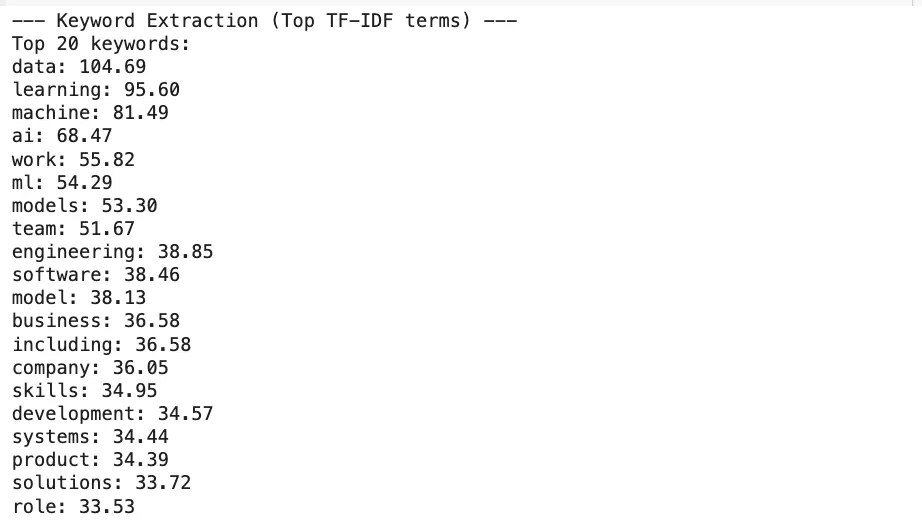
Good, here is the result.

Output
I understand everything other than sexual orientation or gender identity? Interesting.
Final Thoughts
In this one, we have explored another way of automating data analysis. It has been fun, but like always, it has ups and downs. If you want to use a fully automated data analysis tool, test our agent!
Also, we have a bunch of assistants that automate data analysis along with an AI tool that summarizes AI news daily to you! AI to track AI, interesting right?
And for a limited time, all of these features are available for $15 per month. Visit our platform and be one of our founding members! See you there!
Here is the ChatGPT cheat sheet.
Here is the Prompt Techniques cheat sheet.
Here is my NumPy cheat sheet.
Here is the source code of the “How to be a Billionaire” data project.
Here is the source code of the “Classification Task with 6 Different Algorithms using Python” data project.
Here is the source code of the “Decision Tree in Energy Efficiency Analysis” data project.
Here is the source code of the “DataDrivenInvestor 2022 Articles Analysis” data project.
“Machine learning is the last invention that humanity will ever need to make.” Nick Bostrom